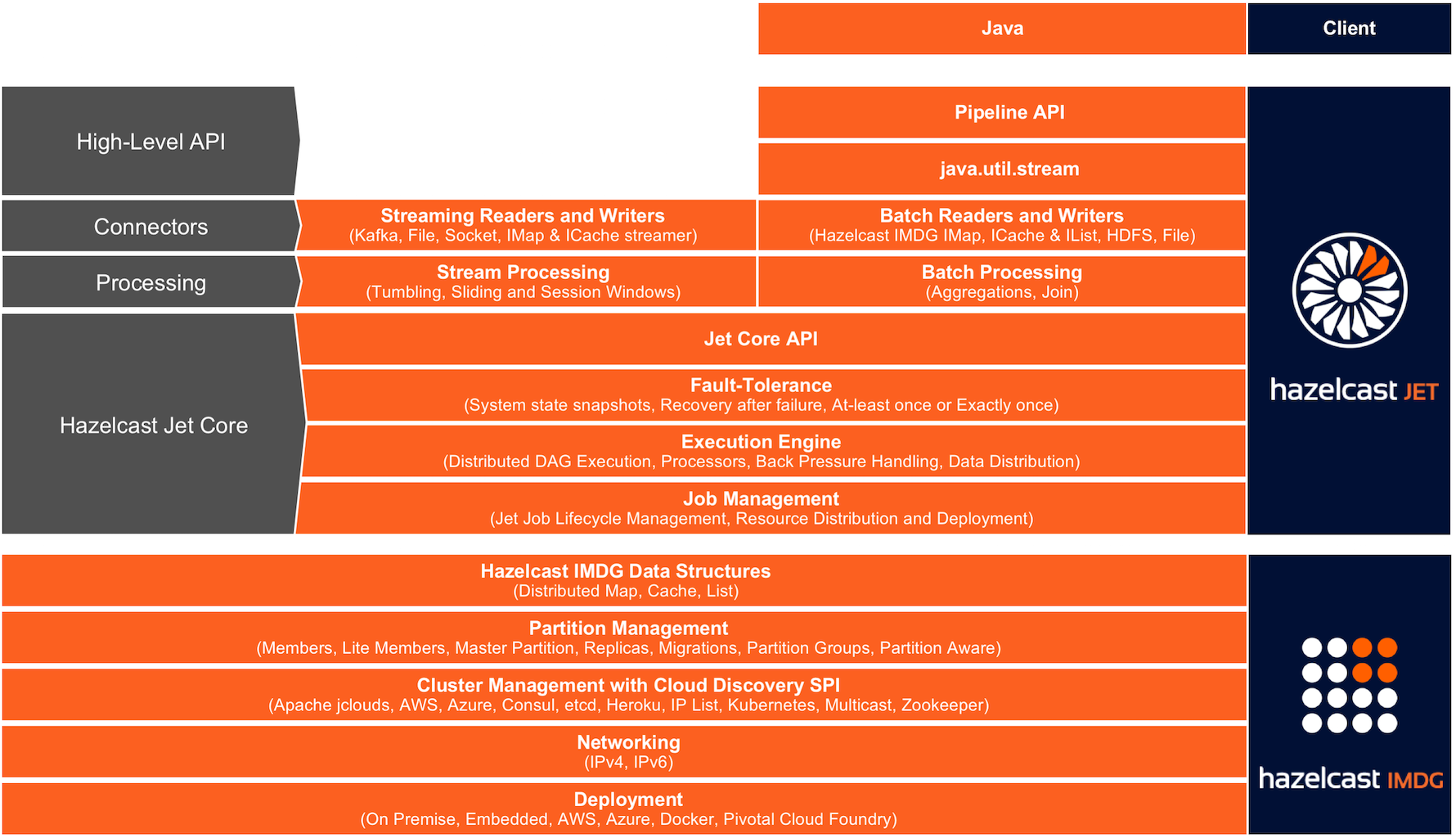
Hazelcast Jet is a distributed data processing engine, built for high-performance batch and stream processing. It reuses some features and services of Hazelcast In-Memory Data Grid (IMDG), but is otherwise a separate product with features not available in the IMDG.
In addition to its own
Pipeline API,
Jet also offers a distributed implementation of
java.util.stream.
You can express your computation over any data source Jet supports using
the familiar API from the JDK 8.
With Hazelcast’s IMDG providing storage functionality, Hazelcast Jet performs parallel execution to enable data-intensive applications to operate in near real-time. Using directed acyclic graphs (DAG) to model relationships between individual steps in the data processing pipeline, Hazelcast Jet can execute both batch and stream-based data processing applications. Jet handles the parallel execution using the green thread approach to optimize the utilization of the computing resources.
Breakthrough application speed is achieved by keeping both the computation and data storage in memory. The embedded Hazelcast IMDG provides elastic in-memory storage and is a great tool for storing the results of a computation or as a cache for datasets to be used during the computation. Extremely low end-to-end latencies can be achieved this way.
It is extremely simple to use -- in particular, Jet can be fully embedded for OEMs and for Microservices – making it is easier for manufacturers to build and maintain next generation systems. Also, Jet uses Hazelcast discovery for finding the members in the cluster, which can be used in both on-premise and cloud environments.
Architecture Overview
The Data Processing Model
Hazelcast Jet provides high performance in-memory data processing by
modeling the computation as a Directed Acyclic Graph (DAG) where
vertices represent computation and edges represent data connections. A
vertex receives data from its inbound edges, performs a step in the
computation, and emits data to its outbound edges. A single vertex's
computation work is performed in parallel by many instances of the
Processor type around the cluster.
One of the major reasons to divide the full computation task into several vertices is data partitioning: the ability to split the data stream traveling over an edge into slices which can be processed independently of each other. To make this work, a function must be defined which computes the partitioning key for each item and makes all related items map to the same key. The computation engine can then route all such items to the same processor instance. This makes it easy to parallelize the computation: each processor will have the full picture for its slice of the entire stream.
Edges determine how the data is routed from individual source processors to individual destination processors. Different edge properties offer precise control over the flow of data.
Clustering and Discovery
Hazelcast Jet typically runs on several machines that form a cluster but it may also run on a single JVM for testing purposes. There are several ways to configure the members for discovery, explained in detail in the Hazelcast IMDG Reference Manual.
Members and Clients
A Hazelcast Jet instance is a unit where the processing takes place. There can be multiple instances per JVM, however this only makes sense for testing. An instance becomes a member of a cluster: it can join and leave clusters multiple times during its lifetime. Any instance can be used to access a cluster, giving an appearance that the entire cluster is available locally.
On the other hand, a client instance is just an accessor to a cluster and no processing takes place in it.
Relationship with Hazelcast IMDG
Hazelcast Jet leans on Hazelcast IMDG for cluster formation and maintenance, data partitioning, and networking. For more information on Hazelcast IMDG, see the latest Hazelcast Reference Manual.
As Jet is built on top of the Hazelcast platform, there is a tight integration between Jet and IMDG. A Jet job is implemented as a Hazelcast IMDG proxy, similar to the other services and data structures in Hazelcast. The Hazelcast Operations are used for different actions that can be performed on a job. Jet can also be used with the Hazelcast Client, which uses the Hazelcast Open Binary Protocol to communicate different actions to the server instance.
Reading from and Writing to Hazelcast Distributed Data Structures
Jet embeds Hazelcast IMDG. Therefore, Jet can use Hazelcast IMDG maps,
caches and lists on the embedded cluster as sources and sinks of data
and make use of data locality. A Hazelcast IMap or ICache is
distributed by partitions across the cluster and Jet members are able to
efficiently read from the Map or Cache by having each member read just
its local partitions. Since the whole IList is stored on a single
partition, all the data will be read on the single member that owns that
partition. When using a map, cache or list as a Sink, it is not possible
to directly make use of data locality because the emitted key-value pair
may belong to a non-local partition. In this case the pair must be
transmitted over the network to the member which owns that particular
partition.
Jet can also use any remote Hazelcast IMDG instance via Hazelcast IMDG connector.
High Availability and Fault Tolerance
Jet provides highly available and fault tolerant distributed computation. If one of the cluster members fails and leaves the cluster during job execution, the job restarted on the remaining members automatically and transparently. Jet achieves this by maintaining in-memory copies of the job metadata inside the cluster. The user does not need to designate any node as the master.
In case of a failure, a batch job can typically just be restarted from beginning as the data can easily be replayed. For streaming jobs that run continuously, this might not be possible so the engine must be able to detect a failure, recover from it, and resume processing without data loss.
Jet achieves fault tolerance in streaming jobs by making a snapshot of the internal processing state at regular intervals. If a member of the cluster fails while a job is running, Hazelcast Jet will detect this and restart the job on the new cluster topology. It will restore its internal state from the snapshot and tell the source to start sending data from the last "committed" position (where the snapshot was taken).
Elasticity
Hazelcast Jet supports the scenario where a new member joins the cluster while a job is running. Currently the ongoing job will not be re-planned to start using the member, though; this is on the roadmap for a future version. The new member can also leave the cluster while the job is running and this won't affect its progress.
One caveat is the special kind of member allowed by the Hazelcast IMDG: a lite member. These members don't get any partitions assigned to them and will malfunction when attempting to run a DAG with partitioned edges. Lite members should not be allowed to join a Jet cluster.