Preface
Welcome to the Hazelcast Jet Reference Manual. This manual includes concepts, instructions, and samples to guide you on how to use Hazelcast Jet to build applications.
As the reader of this manual, you must be familiar with the Java programming language and you should have installed your preferred Integrated Development Environment (IDE).
Naming
- Hazelcast Jet or Jet both refer to the same distributed data processing engine provided by Hazelcast, Inc.
- Hazelcast or Hazelcast IMDG both refer to Hazelcast in-memory data grid middleware. Hazelcast is also the name of the company (Hazelcast, Inc.) providing Hazelcast IMDG and Hazelcast Jet.
License
Hazelcast Jet and Hazelcast Jet Reference Manual are free and provided under the Apache License, Version 2.0.
Trademarks
Hazelcast is a registered trademark of Hazelcast, Inc. All other trademarks in this manual are held by their respective owners.
Getting Help
Support for Hazelcast is provided via GitHub, Hazelcast Jet mailing list and Stack Overflow.
For information on the commercial support for Hazelcast Jet please see hazelcast.com.
Typographical Conventions
Below table shows the conventions used in this manual.
| Convention | Description |
|---|---|
| bold font | - Indicates part of a sentence that requires the reader's specific attention. - Also indicates property/parameter values. |
| italic font | - When italicized words are enclosed with "<" and ">", it indicates a variable in the command or code syntax that you must replace (for example, hazelcast-<version>.jar). - Note and Related Information texts are in italics. |
monospace |
Indicates files, folders, class and library names, code snippets, and inline code words in a sentence. |
| RELATED INFORMATION | Indicates a resource that is relevant to the topic, usually with a link or cross-reference. |
 NOTE NOTE |
Indicates information that is of special interest or importance, for example an additional action required only in certain circumstances. |
| element & attribute | Mostly used in the context of declarative configuration that you perform using an XML file. Element refers to an XML tag used to configure a feature. Attribute is a parameter owned by an element, contributing into the declaration of that element's configuration. Please see the following example.<property name="property1">value1</property>In this example, name is an attribute of the property element. |
Introduction
Hazelcast Jet is a distributed data processing engine, built for high-performance batch and stream processing. It is built on top of Hazelcast In-Memory Data Grid (IMDG) at its foundation, but is a separate product with features not available in Hazelcast.
Hazelcast Jet also introduces the distributed implementation of java.util.stream for Hazelcast IMDG data structures, such as IMap and IList.
Data Processing Model
Hazelcast Jet provides high performance in-memory data processing by modeling
a computation as a Directed Acyclic Graph (DAG) of processing vertices.
Each vertex performs a step in the computation and emits data items
for the vertices it is connected to. A single vertex's
computation work is performed in parallel by many instances of
the Processor type around the cluster. The different vertices are
linked together through edges.
One of the major reasons to divide the full computation task into several vertices is data partitioning: the ability to split the data stream traveling over an edge into slices which can be processed independently of each other. It works by defining a function which computes the partitioning key for each item and makes all related items map to the same key. The computation engine can then route all such items to the same processor instance. This makes it easy to parallelize the computation: each processor will have the full picture for its slice of the entire stream.
Edges determine how the data is routed from individual source processors to individual destination processors. Different edge properties offer precise control over the flow of data.
Clustering and Discovery
Hazelcast Jet typically runs on several machines that form a cluster but it may also run on a single JVM for testing purposes. There are several ways to configure the members for discovery, explained in detail in the Hazelcast IMDG Reference Manual.
Members and Clients
A Hazelcast Jet instance is a unit where the processing takes place. There can be multiple instances per JVM, however this only makes sense for testing. An instance becomes a member of a cluster: it can join and leave clusters multiple times during its lifetime. Any instance can be used to access a cluster, giving an appearance that the entire cluster is available locally.
On the other hand, a client instance is just an accessor to a cluster and no processing takes place in it.
Relationship with Hazelcast IMDG
Hazelcast Jet leans on Hazelcast IMDG with regards to cluster forming and maintenance, data partitioning, and networking. For more information on Hazelcast IMDG, see the latest Hazelcast Reference Manual.
Getting Started
This chapter explains how to start using Hazelcast Jet. It also describes the executable files in the downloaded distribution package.
Requirements
Hazelcast Jet requires a minimum JDK version of 8.
Using Maven and Gradle
The easiest way to start using Hazelcast Jet is to add it as a dependency to your project.
You can find Hazelcast Jet in Maven repositories. Add the following lines to your pom.xml:
<dependencies>
<dependency>
<groupId>com.hazelcast.jet</groupId>
<artifactId>hazelcast-jet</artifactId>
<version>0.3</version>
</dependency>
</dependencies>
If you prefer to use Gradle, execute the following command:
compile 'com.hazelcast.jet:hazelcast-jet:0.3'
Downloading
Alternatively, you can download the latest distribution package for Hazelcast Jet
and add the hazelcast-jet-<version>.jar file to your classpath.
Distribution Package
The distribution package contains the following scripts to help you get started with Hazelcast Jet:
bin/start.shandbin/start.batstart a new Jet member in the current directory.bin/stop.shandbin/stop.batstop the member started in the current directory.bin/cluster.shprovides basic functionality for Hazelcast cluster manager, such as changing the cluster state, shutting down the cluster or forcing the cluster to clean its persisted data.
NOTE: start.sh / start.bat scripts lets you start one Jet member per
folder. To start a new instance, please unzip the package in a new folder.
Quickstart: Word Count
In this example, we will go through building a word count application using Hazelcast Jet.
Starting a Jet Cluster
To start a new Jet cluster, we need to start Jet instances. Typically these would be started on separate machines, but for the purposes of this tutorial we will be using the same JVM for both of the instances. You can start the instances as shown below:
public class WordCount {
public static void main(String[] args) {
JetInstance instance1 = Jet.newJetInstance();
JetInstance instance2 = Jet.newJetInstance();
}
}
These two members should automatically form a cluster, as they will use multicast, by default, to discover each other. You should see an output similar to the following:
Members [2] {
Member [10.0.1.3]:5701 - f1e30062-e87e-4e97-83bc-6b4756ef6ea3
Member [10.0.1.3]:5702 - d7b66a8c-5bc1-4476-a528-795a8a2d9d97 this
}
This means the members successfully formed a cluster. Do not forget to shut down the members afterwards, by adding the following as the last line of your application:
Jet.shutdownAll();
Populating Data
To be able to do a word count, we need some source data. Jet has built-in
readers for maps and lists from Hazelcast, so we will go ahead and
populate an IMap with some lines of text:
IStreamMap<Integer, String> map = instance1.getMap("lines");
map.put(0, "It was the best of times,");
map.put(1, "it was the worst of times,");
map.put(2, "it was the age of wisdom,");
map.put(3, "it was the age of foolishness,");
map.put(4, "it was the epoch of belief,");
map.put(5, "it was the epoch of incredulity,");
map.put(6, "it was the season of Light,");
map.put(7, "it was the season of Darkness");
map.put(8, "it was the spring of hope,");
map.put(9, "it was the winter of despair,");
map.put(10, "we had everything before us,");
map.put(11, "we had nothing before us,");
map.put(12, "we were all going direct to Heaven,");
map.put(13, "we were all going direct the other way --");
map.put(14, "in short, the period was so far like the present period, that some of "
+ "its noisiest authorities insisted on its being received, for good or for "
+ "evil, in the superlative degree of comparison only.");
You might wonder why we are using a map for a sequence of lines. The reason is that the complete list is stored on a single cluster member, whereas the map is sharded according to each entry's key and distributed across the cluster.
Single-threaded Computation
We want to count how many times each word occurs in the text. If we want to do a word count without using a DAG and in a single-threaded computation, we could do it as shown below:
Pattern pattern = Pattern.compile("\\s+");
Map<String, Long> counts = new HashMap<>();
for (String line : map.values()) {
for (String word : pattern.split(line)) {
counts.compute(word.toLowerCase(), (w, c) -> c == null ? 1L : c + 1);
}
}
As soon as we try to parallelize this computation, it becomes clear that we have to model it differently. More complications arise on top of that when we want to scale out across multiple machines.
Modeling Word Count in terms of a DAG
The word count computation can be roughly divided into three steps:
- Read a line from the map ("source" step)
- Split the line into words ("tokenizer" step)
- Update the running totals for each word ("accumulator" step)
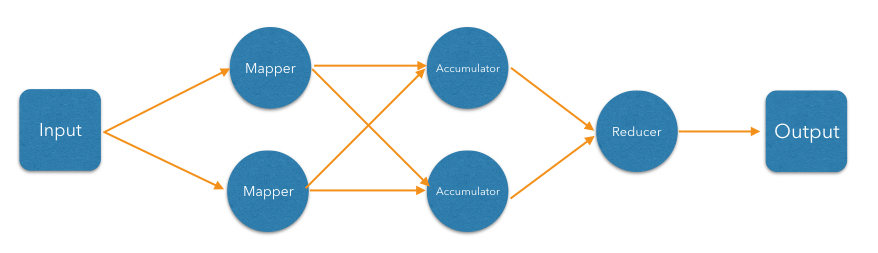
We can represent these steps as a DAG:
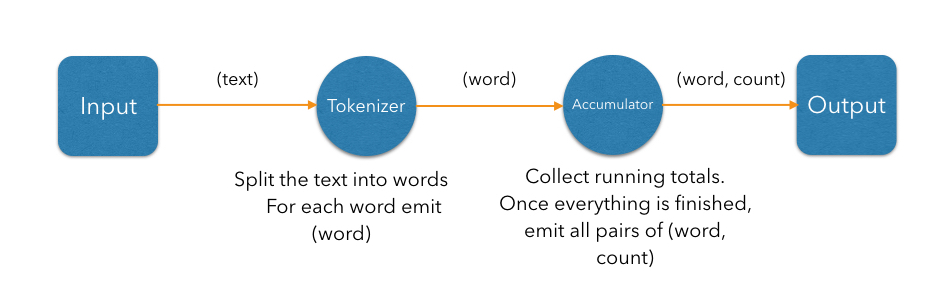
In the simplest case, the computation inside each vertex might be executed in turn in a single-threaded environment. To execute these steps in parallel, a producer vertex must publish its output items to a consumer vertex running on another thread. For this to work efficiently without interference between threads, we need to introduce concurrent queues between the vertices so each thread can do its processing at its own pace.
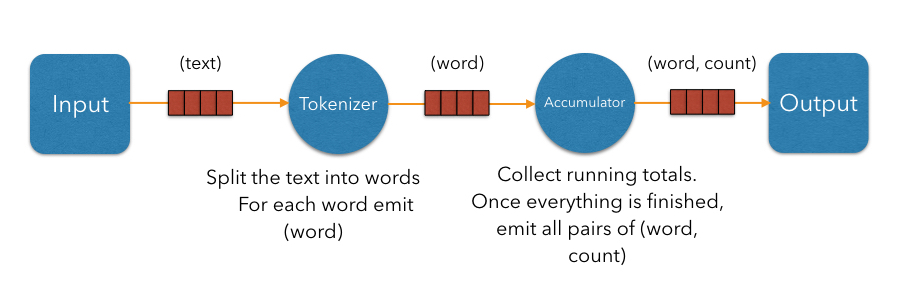
Now let us exploit the parallelizability of line parsing. We can have multiple tokenizer instances, each parsing its subset of lines:
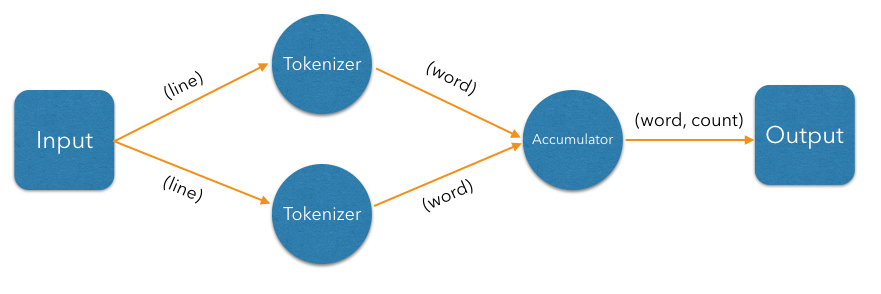
The accumulation step counts occurrences of individual words. Counting one word is independent of counting any other, but we must ensure that for each given word there is a unique instance of accumulator in charge of it, and will receive all entries with that word. This is called partitioning in Jet, and is achieved by creating a partitioned edge in the DAG, which ensures the words with same partitioning key are transmitted to the same instance of the vertex's processor.
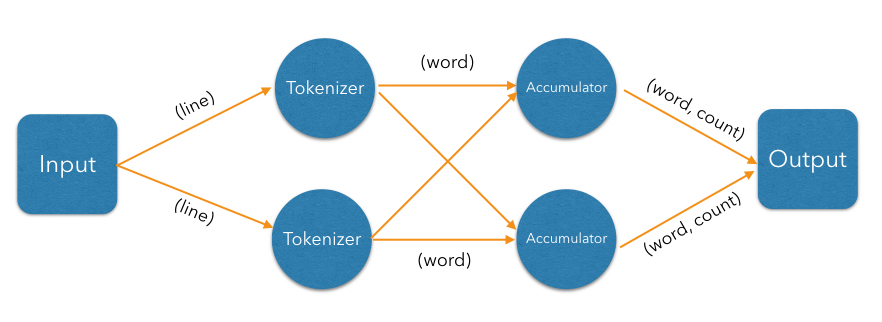
So far our DAG will produce correct results only when executed on a single Jet instance (cluster of size 1). With more members, each will compute just its local counts and then each member will race to push its result to the output map. Fixing this requires the addition of another vertex in the DAG, which will combine results from each local accumulator into a global result:
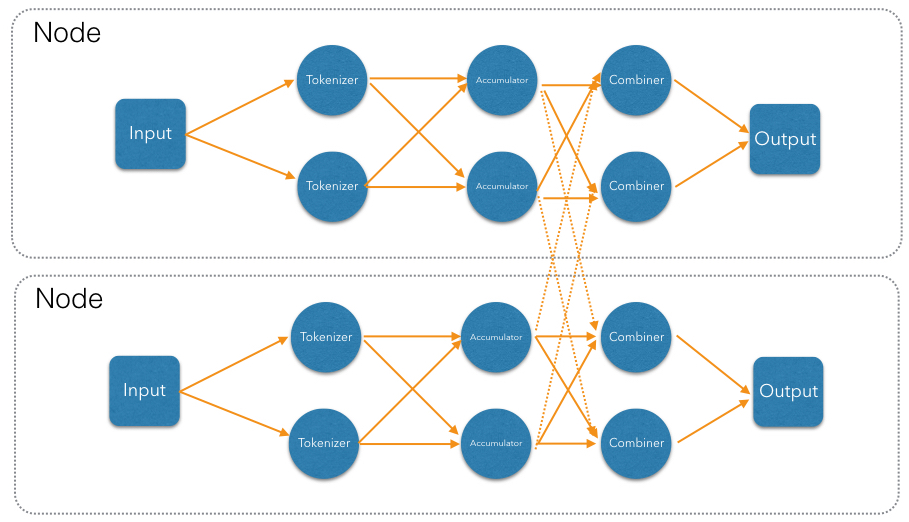
Implementing DAG in Jet
Now we will implement this DAG in Jet. The first step is to create a DAG and source vertex:
DAG dag = new DAG();
Vertex source = dag.newVertex("source", Processors.mapReader("lines"));
This is a simple vertex which will read the lines from the IMap and
emit items of type Map.Entry<Integer, String> to the next vertex. The
key of the entry is the line number, and the value is the line itself.
We can use the built-in map-reading processor here, which can read a
distributed IMap.
The next vertex is the tokenizer. Its responsibility is to take incoming lines and split them into words. This operation can be represented using a flat map processor, which comes built in with Jet:
// line -> words
final Pattern delimiter = Pattern.compile("\\W+");
Vertex tokenizer = dag.newVertex("tokenizer",
flatMap((String line) -> traverseArray(delimiter.split(line.toLowerCase()))
.filter(word -> !word.isEmpty()))
);
This vertex will take an item of type Map.Entry<Integer, String> and
split its value part into words. The key is ignored, as the line number
is not useful for the purposes of word count. There will be one item
emitted for each word, which will be the word itself. The Traverser
interface is a convenience designed to be used by the built-in Jet processors.
The next vertex will do the grouping of the words and emit the count
for each word. We can use the built-in groupAndAccumulate processor.
// word -> (word, count)
Vertex accumulator = dag.newVertex("accumulator",
groupAndAccumulate(() -> 0L, (count, x) -> count + 1)
);
This processor will take items of type String, where the item is the
word. The initial value of the count for a word is zero, and the value
is incremented by one for each time the word is encountered. The
expected output is of the type Entry<String, Long> where the key is
the word, and the value is the accumulated count. The processor can
only emit the final values after it has exhausted all the data.
The accumulation lambda given to the groupAndAccumulate processor
combines the current running count with the count from the new entry.
This vertex will do a local accumulation of word counts on each member. The next step is to do a global accumulation of counts. This is the combining step:
// (word, count) -> (word, count)
Vertex combiner = dag.newVertex("combiner",
groupAndAccumulate(Entry<String, Long>::getKey, initialZero,
(Long count, Entry<String, Long> wordAndCount) -> count + wordAndCount.getValue())
);
This vertex is very similar to the previous accumulator vertex, except we are combining two accumulated values instead of accumulated one for each word.
The final vertex is the output — we want to store the output in another IMap:
Vertex sink = dag.newVertex("sink", Processors.mapWriter("counts"));
Next, we add the vertices we created to our DAG, and connect the vertices together with edges:
dag.edge(between(source, tokenizer))
.edge(between(tokenizer, accumulator)
.partitioned(wholeItem(), HASH_CODE))
.edge(between(accumulator, combiner)
.distributed()
.partitioned(entryKey()))
.edge(between(combiner, sink));
Let's take a closer look at some of the connections between the vertices. First, source and tokenizer:
.edge(between(tokenizer, accumulator)
.partitioned(wholeItem(), HASH_CODE))
The edge between the tokenizer and accumulator is partitioned, because
all entries with the same word as key need to be processed by the same
instance of the vertex. Otherwise the same word would be duplicated
across many instances. The partitioning key is the built-in
wholeItem() partitioner, and we are using the built-in HASH_CODE as
the partitioning function, which uses Object.hashCode().
.edge(between(accumulator, combiner)
.distributed()
.partitioned(entryKey()))
The edge between the accumulator and combiner is also partitioned,
similar to the edge between the generator and accumulator. However,
there is a key difference: the edge is also distributed. A
distributed edge allows items to be sent to other members. Since this
edge is both partitioned and distributed, the partitioning will be across
all the members: all entries with the same word as key will be sent to
a single processor instance in the whole cluster. This ensures that we
get the correct total count for a word.
The partitioning key here is the key part of the Map.Entry<String,
Long>, which is the word. We are using the default partitioning
function here which uses default Hazelcast partitioning. This
partitioning function can be slightly slower than HASH_CODE
partitioning, but is guaranteed to return consistent results across all
JVM processes, so is a better choice for distributed edges.
To run the DAG and print out the results, we simply do the following:
instance1.newJob(dag).execute().get();
System.out.println(instance1.getMap("counts").entrySet());
The final output should look like the following:
[heaven=1, times=2, of=12, its=2, far=1, light=1, noisiest=1,
the=14, other=1, incredulity=1, worst=1, hope=1, on=1, good=1, going=2,
like=1, we=4, was=11, best=1, nothing=1, degree=1, epoch=2, all=2,
that=1, us=2, winter=1, it=10, present=1, to=1, short=1, period=2,
had=2, wisdom=1, received=1, superlative=1, age=2, darkness=1, direct=2,
only=1, in=2, before=2, were=2, so=1, season=2, evil=1, being=1,
insisted=1, despair=1, belief=1, comparison=1, some=1, foolishness=1,
or=1, everything=1, spring=1, authorities=1, way=1, for=2]
An executable version of this sample can be found at the Hazelcast Jet code samples repository.
Understanding Configuration
You can configure Hazelcast Jet either programmatically or declaratively (XML).
Configuring Programmatically
Programmatic configuration is the simplest way to configure Jet. For example, the following will configure Jet to use only two threads for cooperative execution:
JetConfig config = new JetConfig();
config.getInstanceConfig().setCooperativeThreadCount(2);
JetInstance jet = Jet.newJetInstance(config);
Any XML configuration files that might be present will be ignored when programmatic configuration is used.
Configuring Declaratively
It is also possible to configure Jet through XML files when a
JetInstance is created without any explicit JetConfig file. Jet will
look for a configuration file in the following order:
- Check the system property
hazelcast.jet.config. If the value is set, and starts withclasspath:, then it will be treated as a classpath resource. Otherwise, it will be treated as a file reference. - Check for the presence of
hazelcast-jet.xmlin the working directory. - Check for the presence of
hazelcast-jet.xmlin the classpath. - If all the above checks fail, then the default XML configuration will be loaded.
An example configuration looks like the following:
<hazelcast-jet xsi:schemaLocation="http://www.hazelcast.com/schema/jet-config hazelcast-jet-config-0.3.xsd"
xmlns="http://www.hazelcast.com/schema/jet-config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<instance>
<!-- number of threads to use for DAG execution -->
<cooperative-thread-count>8</cooperative-thread-count>
<!-- frequency of flow control packets, in milliseconds -->
<flow-control-period>100</flow-control-period>
<!-- working directory to use for placing temporary files -->
<temp-dir>/var/tmp/jet</temp-dir>
</instance>
<properties>
<property name="custom.property">custom property</property>
</properties>
<edge-defaults>
<!-- number of available slots for each concurrent queue between two vertices -->
<queue-size>1024</queue-size>
<!-- number of slots before high water is triggered for the outbox -->
<high-water-mark>2048</high-water-mark>
<!-- maximum packet size in bytes, only applies to distributed edges -->
<packet-size-limit>16384</packet-size-limit>
<!-- target receive window size multiplier, only applies to distributed edges -->
<receive-window-multiplier>3</receive-window-multiplier>
</edge-defaults>
<!-- custom properties which can be read within a ProcessorSupplier -->
</hazelcast-jet>
The following table lists the configuration elements for Hazelcast Jet:
| Name | Description | Default Value |
|---|---|---|
| Cooperative Thread Count | Maximum number of cooperative threads to be used for execution of jobs. | Runtime.getRuntime().availableProcessors() |
| Temp Directory | Directory where temporary files will be placed, such as JAR files submitted by clients. | Jet will create a temp directory, which will be deleted on exit. |
| Flow Control Period | While executing a Jet job there is the issue of regulating the rate at which one member of the cluster sends data to another member. The receiver will regularly report to each sender how much more data it is allowed to send over a given DAG edge. This option sets the length (in milliseconds) of the interval between flow-control packets. | 100ms |
| Edge Defaults | The default values to be used for all edges. | Please see the Tuning Edges section. |
Configuring Underlying Hazelcast Instance
Each Jet member or client, will have a respective underlying Hazelcast member or client. Please refer to the Hazelcast Reference Manual for specific configuration options for Hazelcast IMDG.
Programmatic
The underlying Hazelcast IMDG member can be configured as follows:
JetConfig jetConfig = new JetConfig();
jetConfig.getHazelcastConfig().getGroupConfig().setName("test");
JetInstance jet = Jet.newJetInstance(jetConfig);
The underlying Hazelcast IMDG client can be configured as follows:
ClientConfig clientConfig = new ClientConfig();
clientConfig.getGroupConfig().setName("test");
JetInstance jet = Jet.newJetClient(clientConfig);
Declarative
The underlying Hazelcast IMDG configuration can also be updated declaratively. Please refer to the Hazelcast Reference Manual for information on how to do this.
Implementing Custom Sources and Sinks
Hazelcast Jet provides a flexible API that makes it easy to implement your own
custom sources and sinks. Both sources and sinks are implemented using
the same API as the rest of the Processors.
In this chapter we will work through some examples as a guide to how you
can connect Jet with your own data sources.
Sources
One of the main concerns when writing custom sources is that the source is typically distributed across multiple machines and partitions, and the work needs to be distributed across multiple members and processors.
Jet provides a flexible ProcessorMetaSupplier and ProcessorSupplier
API which can be used to control how a source is distributed across the
network.
The procedure for generating Processor instances is as follows:
- The
ProcessorMetaSupplierfor theVertexis serialized and sent to the coordinating member. - The coordinator calls
ProcessorMetaSupplier.get()once for each member in the cluster and aProcessorSupplieris created for each member. - The
ProcessorSupplierfor each member is serialized and sent to that member. - Each member will call their own
ProcessorSupplierwith the correct count parameter, which corresponds to thelocalParallelismsetting of that vertex.
Example: Distributed Integer Generator
Let's say we want to write a simple source, which generates numbers from
0 to 1,000,000 (exclusive). It is trivial to write a single Processor
which can do this using java.util.stream and Traverser.
public static class NumberGenerator extends AbstractProcessor {
private final Traverser<Integer> traverser;
public NumberGenerator(int limit) {
traverser = traverseStream(IntStream.range(0, limit).boxed());
}
@Override
public boolean complete() {
return emitCooperatively(traverser);
}
}
We will also add a simple logging processor, so we can see what values are generated and received:
public static class PeekProcessor extends AbstractProcessor {
@Override
protected boolean tryProcess(int ordinal, @Nonnull Object item) {
System.out.println("Received number: " + item);
emit(item);
return true;
}
}
You can then build your DAG as follows and execute it:
final int limit = 10;
dag.newVertex("number-generator", () -> new NumberGenerator(limit));
// Vertex logger = dag.newVertex("logger-vertex", PeekProcessor::new);
dag.edge(Edge.between(generator, logger));
jet.newJob(dag).execute().get();
When you run this code, you will see the output as below:
Received number: 4
Received number: 0
Received number: 3
Received number: 2
Received number: 2
Received number: 2
Since we are using the default parallelism setting on this vertex, several instances of this processor are created, all of which will be generating the same sequence of values.
What we actually want is to generate a subset of the values for each processor. We will start by partitioning the data according to its remainder, when divided by the total number of processors. For example, if we have 8 processors, numbers which have a remainder of 1 when divided by 8, will go to processor with index 1.
To do this, we need to implement the ProcessorSupplier API:
static class NumberGeneratorSupplier implements ProcessorSupplier {
private final int limit;
public NumberGeneratorSupplier(int limit) {
this.limit = limit;
}
@Nonnull
@Override
public List<? extends Processor> get(int count) {
// each processor is responsible for a subset of the numbers.
return IntStream.range(0, count)
.mapToObj(index ->
new NumberGenerator(IntStream.range(0, limit)
.filter(n -> n % count == index))
)
.collect(Collectors.toList());
}
}
static class NumberGenerator extends AbstractProcessor {
private final Traverser<Integer> traverser;
public NumberGenerator(IntStream stream) {
traverser = traverseStream(stream.boxed());
}
@Override
public boolean complete() {
return emitCooperatively(traverser);
}
}
With this approach, each instance of processor will only generate a
subset of the numbers, with each instance generating the numbers where
the remainder of the number divided count matches the index of the
processor.
If we add another member to the cluster, we will quickly see that both
members are generating the same sequence of numbers. We need to distribute
the work across the cluster, by making sure that each member will generate
a subset of the numbers. We will again follow a similar approach as
above, but now we need to be aware of the global index for each
Processor instance.
To achieve this, we need to implement a custom ProcessorMetaSupplier.
A ProcessorMetaSupplier is called from a single coordinator member,
and creates one ProcessorSupplier for each member. The main partition
allocation thus can be done by the ProcessorMetaSupplier. Our
distributed number generator source could then look as follows:
static class NumberGeneratorMetaSupplier implements ProcessorMetaSupplier {
private final int limit;
private transient int totalParallelism;
private transient int localParallelism;
NumberGeneratorMetaSupplier(int limit) {
this.limit = limit;
}
@Override
public void init(@Nonnull Context context) {
totalParallelism = context.totalParallelism();
localParallelism = context.localParallelism();
}
@Override @Nonnull
public Function<Address, ProcessorSupplier> get(@Nonnull List<Address> addresses) {
Map<Address, ProcessorSupplier> map = new HashMap<>();
for (int i = 0; i < addresses.size(); i++) {
Address address = addresses.get(i);
int start = i * localParallelism;
int end = (i + 1) * localParallelism;
int mod = totalParallelism;
map.put(address, count -> range(start, end)
.mapToObj(index -> new NumberGenerator(range(0, limit).filter(f -> f % mod == index)))
.collect(toList())
);
}
return map::get;
}
}
The vertex creation can then be updated as follows:
Vertex generator = dag.newVertex("number-generator", new NumberGeneratorMetaSupplier(limit));
Sinks
Like the sources, sinks are just another kind of Processors. Sinks are
typically implemented as AbstractProcessor and implement the
tryProcess method, and write each incoming item to the sink.
Example: File Writer
In this example, we will implement a simple DAG that dumps a Hazelcast IMap into a folder.
As file writing will be distributed, we want each Processor writing to a separate file, but within the same folder.
We can achieve this by implementing a ProcessorSupplier and
a corresponding Processor:
static class Supplier implements ProcessorSupplier {
private final String path;
private transient List<Writer> writers;
Supplier(String path) {
this.path = path;
}
@Override
public void init(@Nonnull Context context) {
new File(path).mkdirs();
}
@Nonnull @Override
public List<Writer> get(int count) {
return writers = range(0, count)
.mapToObj(e -> new Writer(path))
.collect(Collectors.toList());
}
@Override
public void complete(Throwable error) {
writers.forEach(p -> {
try {
p.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
});
}
}
It can be seen in the implementation that ProcessorSupplier holds a
reference to all the Processors. This is not normally necessary, but in
this case we want to be able to close all the file writers gracefully
when the job execution is completed. complete() in ProcessorSupplier
is always called, even if the job fails with an exception or is
cancelled.
The Processor implementation itself is fairly straightforward:
static class Writer extends AbstractProcessor implements Closeable {
static final Charset UTF8 = Charset.forName("UTF-8");
private final String path;
private transient BufferedWriter writer;
Writer(String path) {
this.path = path;
}
@Override
protected void init(@Nonnull Context context) throws Exception {
Path path = Paths.get(this.path, context.jetInstance().getName() + "-" + context.index());
try {
writer = Files.newBufferedWriter(path, UTF8);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
protected boolean tryProcess(int ordinal, @Nonnull Object item) throws Exception {
writer.append(item.toString());
writer.newLine();
return true;
}
@Override
public boolean isCooperative() {
return false;
}
@Override
public void close() throws IOException {
if (writer != null) {
writer.close();
}
}
}
The init method appends the current member name as well as the processor
index to the file name. This ensures that each Processor instance is
writing to a unique file.
The close method is called by the Supplier, after the job execution is
completed.
This processor is also marked as non-cooperative since it makes blocking calls to the file system.
java.util.stream Support for Hazelcast IMDG
Hazelcast Jet adds distributed java.util.stream support for Hazelcast IMap and
IList data structures.
For extensive information about java.util.stream API please refer to
the official javadocs.
Simple Example
JetInstance jet = Jet.newJetInstance();
IStreamMap<String, Integer> map = jet.getMap("latitudes");
map.put("London", 51);
map.put("Paris", 48);
map.put("NYC", 40);
map.put("Sydney", -34);
map.put("Sao Paulo", -23);
map.put("Jakarta", -6);
map.stream().filter(e -> e.getValue() < 0).forEach(System.out::println);
Serializable Lambda Functions
By default, the functional interfaces which were added to
java.util.function are not serializable. In a distributed system, the
defined lambdas need to be serialized and sent to the other members. Jet
includes the serializable version of all the interfaces found in the
java.util.function which can be accessed using the
com.hazelcast.jet.stream.Distributed class.
Special Collectors
Like with the functional interfaces, Jet also includes the distributed
versions of the classes found in java.util.stream.Collectors. These
can be reached via com.hazelcast.jet.stream.DistributedCollectors.
This class also contains a few of additional collectors worth a special
mention:
toIMap(): A collector which will write the data directly to a new HazelcastIMap. Unlike with the standardtoMap()collector, the whole map does not need to be transferred to the client.groupingByToIMap(): A collector which will perform a grouping operation and write the results to a HazelcastIMap. This uses a more efficient implementation than the standardgroupingBy()collector.toIList(): A collector which will write the output to a new HazelcastIList. Unlike with the standardtoList()collector, the list does not need to be transferred as a whole to the client.
Word Count
The word count example that was described in the Quickstart:Word Count chapter can
be rewritten using the java.util.stream API as follows:
IMap<String, Long> counts = lines
.stream()
.flatMap(m -> Stream.of(PATTERN.split(m.getValue().toLowerCase())))
.collect(DistributedCollectors.toIMap(w -> w, w -> 1L, (left, right) -> left + right));
Implementation Notes
Jet's java.util.stream implementation will automatically convert a
stream into a DAG when one of the terminal methods are called. The DAG
creation is done lazily, and only if a terminal method is called.
The following DAG will be compiled as follows:
IStreamMap<String, Integer> ints = jet.getMap("ints");
int result = ints.stream().map(Entry::getValue)
.reduce(0, (l, r) -> l + r);
Understanding the Jet Architecture and API
This chapter provides an overview to the Hazelcast Jet's architecture and API units and elements.
DAG
At the core of Jet is the distributed computation engine based on the paradigm of a directed acyclic graph (DAG). In this graph, vertices are units of data processing and edges are units of data routing and transfer.
Job
Job is a handle to the execution of a DAG. To create a job,
supply the DAG to a previously created JetInstance as shown below:
JetInstance jet = Jet.newJetInstance(); // or Jet.newJetClient();
DAG dag = new DAG();
dag.newVertex(..);
jet.newJob(dag).execute().get();
As hinted in the code example, the job submission API is identical
whether you use it from a client machine or directly on an instance of a
Jet cluster member. This works because the Job instance is
serializable and the client can send it over the network when submitting
the job. The same Job instance can be submitted for execution many
times.
Job execution is asynchronous. The execute() call returns as soon as
the Jet cluster has been contacted and the serialized job is sent to it.
The user gets a Future which can be inspected or waited on to find out
the outcome of a computation job. It is also cancelable and can send a
cancelation command to the Jet cluster.
Note that the Future only signals the status of the job, it does not
contain the result of the computation. The DAG explicitly models the
storing of results via its sink vertices. Typically the results will
be in a Hazelcast map or another structure and have to be accessed by
their own API after the job is done.
Deploying the Resource
If the Jet cluster has not been started with all the job's computation code already on the classpath, you have to deploy the code together with the Job instance:
JobConfig config = new JobConfig();
config.addJar("..");
jet.newJob(dag, config).execute().get();
When persisting and reading data from the underlying Hazelcast IMDG instance, it is important to be aware that the deployed code is used only within the scope of the executing Jet job.
Vertex
Vertex is the main unit of work in a Jet computation. Conceptually, it
receives input from its inbound edges and emits data to its outbound
edges. Practically, it is a number of Processor instances which
receive each of its own part of the full stream traveling over the inbound
edges, and likewise emits its own part of the full stream going down
the outbound edges.
Edge Ordinal
An edge is connected to a vertex with a given ordinal, which identifies it to the vertex and its processors. When a processor receives an item, it knows the ordinal of the edge on which the item came in. Things are similar on the outbound side: the processor emits an item to a given ordinal, but also has the option to emit the same item to all ordinals. This is the most typical case and allows easy replication of a data stream across several edges.
In the DAG-building API the default value of the ordinal is 0. There must be no gaps in ordinal assignment, which means a vertex will have inbound edges with ordinals 0..N and outbound edges with ordinals 0..M.
Source and Sink
Jet uses only one kind of vertex, but in practice there is an important distinction between the following:
- internal vertex which accepts input and transforms it into output,
- source vertex which generates output without receiving anything,
- sink vertex which consumes input and does not emit anything.
Sources and sinks must interact with the environment to store/load data, making their implementation more involved compared to the internal vertices, whose logic is self-contained.
Local and Global Parallelism
The vertex is implemented by one or more instances of Processor on
each member. Each vertex can specify how many of its processors will run
per cluster member using the localParallelism property; every member
will have the same number of processors. A new Vertex instance has
this property set to -1, which requests to use the default value equal
to the configured size of the cooperative thread pool. The latter
defaults to Runtime.availableProcessors().
The global parallelism of the vertex is also an important value, especially in terms of the distribution of partitions among processors. It is equal to local parallelism multiplied by the cluster size.
Processor
Processor is the main type whose implementation is up to the user: it
contains the code of the computation to be performed by a vertex. There
are a number of Processor building blocks in the Jet API which allow you
to just specify the computation logic, while the provided code
handles the processor's cooperative behavior. Please refer to the
AbstractProcessor section.
A processor's work can be conceptually described as follows: "receive
data from zero or more input streams and emit data into zero or more
output streams." Each stream maps to a single DAG edge (either inbound
or outbound). There is no requirement on the correspondence between
input and output items; a processor can emit any data it sees fit,
including none at all. The same Processor abstraction is used for all
kinds of vertices, including sources and sinks.
Cooperative Multithreading
Cooperative multithreading is one of the core features of Jet and can be
roughly compared to green
threads. It is purely a
library-level feature and does not involve any low-level system or JVM
tricks; the Processor API is simply designed in such a
way that the processor can do a small amount of work each time it is
invoked, then yield back to the Jet engine. The engine manages a thread
pool of fixed size and on each thread, the processors take their turn in
a round-robin fashion.
The point of cooperative multithreading is much lower context-switching cost and precise knowledge of the status of a processor's input and output buffers, which determines its ability to make progress.
Processor instances are cooperative by default. The processor can opt
out of cooperative multithreading by overriding isCooperative() to
return false. Jet will then start a dedicated thread for it.
Requirements for a Cooperative Processor
To maintain an overall good throughput, a cooperative processor must take care not to hog the thread for too long (a rule of thumb is up to a millisecond at a time). Jet's design strongly favors cooperative processors and most processors can and should be implemented to fit these requirements. The major exception are sources and sinks because they often have no choice but calling into blocking I/O APIs.
Outbox
The processor deposits the items it wants to emit to an instance of
Outbox, which has a separate bucket for each outbound edge. The
buckets are unbounded, but each has a defined "high water mark" that
says when the bucket should be considered full. When the processor
realizes it has hit the high water mark, it should return from the
current processing callback and let the execution engine drain the
outbox.
Data-processing Callbacks
Three callback methods are involved in data processing: process(),
completeEdge(), and complete().
Processors can be stateful and do not need to be thread-safe. A single instance will be called by a single thread at a time, although not necessarily always the same thread.
process()
Jet passes the items received over a given edge by calling
process(ordinal, inbox). All items received since the last process()
call are in the inbox, but also all the items the processor has not
removed in a previous process() call. There is a separate instance of
Inbox for each inbound edge, so any given process() call involves
items from only one edge.
The processor should not remove an item from the inbox until it has
fully processed it. This is important with respect to the cooperative
behavior: the processor may not be allowed to emit all items
corresponding to a given input item and may need to return from the
process() call early, saving its state. In such a case the item should
stay in the inbox so Jet knows the processor has more work to do even if
no new items are received.
completeEdge()
Eventually each edge will signal that its data stream is exhausted. When this
happens, Jet calls the processor's completeEdge() with the ordinal of
the completed edge.
The processor may want to emit any number of items upon this event, and
it may be prevented from emitting all due to a full outbox. In this case
it may return false and will be called again later.
complete()
Jet calls complete() after all the edges are exhausted and all the
completeEdge() methods are called. It is the last method to be invoked on
the processor before disposing of it. The semantics of the boolean
return value are the same as in completeEdge().
Creating and Initializing Jobs
These are the steps taken to create and initialize a Jet job:
- The user builds the DAG and submits it to the local Jet client instance.
- The client instance serializes the DAG and sends it to a member of the Jet cluster. This member becomes the coordinator for this Jet job.
- The coordinator deserializes the DAG and builds an execution plan for each member.
- The coordinator serializes the execution plans and distributes each to its target member.
- Each member acts upon its execution plan by creating all the needed tasklets, concurrent queues, network senders/receivers, etc.
- The coordinator sends the signal to all members to start job execution.
The most visible consequence of the above process is the
ProcessorMetaSupplier type: you must provide one for each
Vertex. In Step 3, the coordinator deserializes the meta-supplier as a
constituent of the DAG and asks it to create ProcessorSupplier
instances which go into the execution plans. A separate instance of
ProcessorSupplier is created specifically for each member's plan. In
Step 4, the coordinator serializes these and sends each to its member. In
Step 5 each member deserializes its ProcessorSupplier and asks it to
create as many Processor instances as configured by the vertex's
localParallelism property.
This process is so involved because each Processor instance may need
to be differently configured. This is especially relevant for processors
driving a source vertex: typically each one will emit only a slice of
the total data stream, as appropriate to the partitions it is in charge
of.
ProcessorMetaSupplier
This type is designed to be implemented by the user, but the
Processors utility class provides implementations covering most cases.
You may need custom meta-suppliers primarily to implement a
custom data source or sink. Instances of this type are serialized and
transferred as a part of each Vertex instance in a DAG. The
coordinator member deserializes it to retrieve ProcessorSuppliers.
Before being asked for ProcessorSuppliers, the meta-supplier is given
access to the Hazelcast instance so it can find out the parameters of
the cluster the job will run on. Most typically, the meta-supplier in
the source vertex will use the cluster size to control the assignment of
data partitions to each member.
ProcessorSupplier
Usually this type will be custom-implemented in the same cases where its
meta-supplier is custom-implemented and complete the logic of a
distributed data source's partition assignment. It supplies instances of
Processor ready to start executing the vertex's logic.
Please see the Implementing Custom Sources and Sinks section for more guidance on how these interfaces can be implemented.
Convenience API to Implement a Processor
AbstractProcessor
AbstractProcessor is a convenience class designed to deal with most of
the boilerplate in implementing the full Processor API.
The first line of convenience are the tryProcessN() methods which
receive one item at a time, thus eliminating the need to write a
suspendable loop over the input items. There is a separate method
specialized for each edge from 0 to 4 (tryProcess0..tryProcess4) and
there is a catch-all method tryProcessAny(ordinal, item). If the
processor does not need to distinguish between the inbound edges, the latter
method is a good match; otherwise, it is simpler to implement one or more
of the ordinal-specific methods. The catch-all method is also the only
way to access inbound edges beyond ordinal 4, but such cases are very
rare in practice.
A major complication arises from the requirement to observe the outbox limits during a single processing step. If the processor emits many items per step, the loop doing this must support being suspended at any point and resumed later. This need arises in two typical cases:
- when a single input item maps to a multitude of output items,
- when items are emitted in the final step, after having received all the input.
AbstractProcessor provides the method emitCooperatively to support
the latter and there is additional support for the former with the
nested class FlatMapper. These work with the Traverser abstraction
to cooperatively emit a user-provided sequence of items.
Traverser
Traverser is a very simple functional interface whose shape matches
that of a Supplier, but with a contract specialized for the traversal
over a sequence of non-null items: each call to its next() method
returns another item of the sequence until exhausted, then keeps
returning null. The point of this type is the ability to implement
traversal over any kind of dataset or lazy sequence with minimum hassle:
often just by providing a one-liner lambda expression. This makes it
very easy to integrate into Jet's convenience APIs for cooperative
processors.
Traverser also supports some default methods that facilitate building
a simple transformation layer over the underlying sequence: map,
filter, and flatMap.
Simple Example
The following example shows how you can implement a simple flatmapping processor:
public class ItemAndSuccessorP extends AbstractProcessor {
private final FlatMapper<Integer, Integer> flatMapper =
flatMapper(i -> traverseIterable(asList(i, i + 1)));
@Override
protected boolean tryProcess(int ordinal, Object item) {
return flatMapper.tryProcess((int) item);
}
}
For each received Integer item this processor emits the item and its
successor. It does not differentiate between inbound edges (treats data
from all edges the same way) and emits each item to all outbound edges
connected to its vertex.
Processors Utility Class
As a further layer of convenience, there are some ready-made Processor implementations. These are the broad categories:
- Sources and sinks for Hazelcast
IMapandIList. - Processors with
flatMap-type logic, includingmap,filter, and the most generalflatMap. - Processors that perform a reduction operation after grouping items by key. These come in two flavors: a. Accumulate: reduce by transforming an immutable value. b. Collect: reduce by updating a mutable result container.
Please refer to the Processors Javadoc for further details.
Edge
An edge represents a link between two vertices in the DAG. Conceptually,
data flows between two vertices along an edge; practically, each
processor of the upstream vertex contributes to the overall data stream
over the edge and each processor of the downstream vertex receives a
part of that stream. Several properties of the Edge control the
routing from upstream to downstream processors.
For any given pair of vertices, there can be at most one edge between them.
Priority
By default the processor receives items from all inbound edges as they arrive. However, there are important cases where the reception of one edge must be delayed until all other edges are consumed in full. A major example is a join operation. Collating items from several edges by a common key implies buffering the data from all edges except one before emitting any results. Often there is one edge with much more data than the others and this one does not need to be buffered if all the other data is ready.
Edge consumption order is controlled by the priority property. Edges are sorted by their priority number (ascending) and consumed in that order. Edges with the same priority are consumed without particular ordering (as the data arrives).
Local and Distributed Edges
A major choice to make in terms of data routing is whether the candidate
set of target processors is unconstrained, encompassing all processors
across the cluster, or constrained to just those running on the same
cluster member. This is controlled by the distributed property of the
edge. By default the edge is local and calling the distributed()
method removes this restriction.
With appropriate DAG design, network traffic can be minimized by
employing local edges. Local edges are implemented with the most
efficient kind of concurrent queue: single-producer, single-consumer
bounded queue. It employs wait-free algorithms on both sides and avoids
volatile writes by using lazySet.
Forwarding Patterns
The forwarding pattern decides which of the processors in the candidate set to route each particular item to.
Variable Unicast
This is the default forwarding pattern. For each item a single destination processor is chosen with no further restrictions on the choice. The only guarantee given by this pattern is that the item will be received by exactly one processor, but typically care will be taken to "spray" the items equally over all the reception candidates.
This choice makes sense when the data does not have to be partitioned, usually implying a downstream vertex which can compute the result based on each item in isolation.
Broadcast
A broadcasting edge sends each item to all candidate receivers. This is useful when some small amount of data must be broadcast to all downstream vertices. Usually such vertices will have other inbound edges in addition to the broadcasting one, and will use the broadcast data as context while processing the other edges. In such cases the broadcasting edge will have a raised priority. There are other useful combinations, like a parallelism-one vertex that produces the same result on each member.
Partitioned
A partitioned edge sends each item to the one processor responsible for the item's partition ID. On a distributed edge, this processor will be unique across the whole cluster. On a local edge, each member will have its own processor for each partition ID.
Each processor can be assigned to multiple partitions. The global number of partitions is controlled by the number of partitions in the underlying Hazelcast IMDG configuration. Please refer to Hazelcast Reference Manual for more information about Hazelcast IMDG partitioning.
This is the default algorithm to determine the partition ID of an item:
- Apply the
keyExtractorfunction defined on the edge to retrieve the partitioning key. - Serialize the partitioning key to a byte array using Hazelcast serialization.
- Apply Hazelcast's standard
MurmurHash3-based algorithm to get the key's hash value. - Partition ID is the hash value modulo the number of partitions.
The above procedure is quite CPU-intensive, but has the essential property of giving repeatable results across all cluster members, which may be running on disparate JVM implementations.
Another common choice is to use Java's standard Object.hashCode(). It
is often significantly faster. However, it is not a safe strategy in
general because hashCode()'s contract does not require repeatable
results across JVMs, or even different instances of the same JVM
version.
You can provide your own implementation of Partitioner to gain full
control over the partitioning strategy.
All to One
The all-to-one forwarding pattern is a special-case of the partitioned pattern where all items are assigned to the same partition ID, randomly chosen at the job initialization time. This will direct all items to the same processor.
Buffered Edges
In some special cases, unbounded data buffering must be allowed on an edge. Consider the following scenario:
A vertex sends output to two edges, creating a fork in the DAG. The branches later rejoin at a downstream vertex which assigns different priorities to its two inbound edges. Since the data for both edges is generated simultaneously, and since the lower-priority edge will apply backpressure while waiting for the higher-priority edge to be consumed in full, the upstream vertex will not be allowed to emit its data and a deadlock will occur. The deadlock is resolved by activating the unbounded buffering on the lower-priority edge.
Tuning Edges
Edges have some configuration properties which can be used for tuning how the items are transmitted. The following options are available:
| Name | Description | Default Value |
|---|---|---|
| High Water Mark | A Processor deposits its output items to its Outbox. It is an unbounded buffer, but has a "high water mark" which should be respected by a well-behaving processor. When its outbox reaches the high water mark,the processor should yield control back to its caller. | 2048 |
| Queue Size |
When data needs to travel between two processors on the same
cluster member, it is sent over a concurrent single-producer,
single-consumer (SPSC) queue of fixed size. This options controls
the size of the queue.
Since there are several processors executing the logic of each vertex, and since the queues are SPSC, there will be a total of senderParallelism * receiverParallelism queues
representing the edge on each member. Care should be taken to
strike a balance between performance and memory usage.
|
1024 |
| Packet Size Limit |
For a distributed edge, data is sent to a remote member via
Hazelcast network packets. Each packet is dedicated to the data of
a single edge, but may contain any number of data items. This
setting limits the size of the packet in bytes. Packets should be
large enough to drown out any fixed overheads, but small enough to
allow good interleaving with other packets.
Note that a single item cannot straddle packets, therefore the maximum packet size can exceed the value configured here by the size of a single data item. This setting has no effect on a non-distributed edge. |
16384 |
| Receive Window Multiplier |
For each distributed edge the receiving member regularly sends
flow-control ("ack") packets to its sender which prevent it from
sending too much data and overflowing the buffers. The sender is
allowed to send the data one receive window further than the last
acknowledged byte and the receive window is sized in proportion to
the rate of processing at the receiver.
Ack packets are sent in regular intervals and the receive window multiplier sets the factor of the linear relationship between the amount of data processed within one such interval and the size of the receive window. To put it another way, let us define an ackworth to be the amount of data processed between two consecutive ack packets. The receive window multiplier determines the number of ackworths the sender can be ahead of the last acked byte. This setting has no effect on a non-distributed edge. |
3 |
Additional Modules
Hazelcast Jet comes with some additional modules that can be used to connect to additional data sources and sinks.
These modules are currently under active development and are only meant for testing.
hazelcast-jet-hadoop
HdfsReader and HdfsWriter classes can be used to read and write to
Apache Hadoop. Currently only the
TextInputFormat and TextOutputFormat formats are supported.
The Hadoop module will perform best when the Jet cluster runs on the same members as the data members and will take data locality into account when reading from HDFS.
hazelcast-jet-kafka
KafkaReader and KafkaWriter can be used to read a stream of data from
Apache Kafka. Kafka partitions will be
distributed across Jet processors, with each Jet processors being assigned
one or more partitions.