The word count computation can be roughly divided into three steps:
- Read a line from the map ("source" step)
- Split the line into words ("tokenizer" step)
- Update the running totals for each word ("accumulator" step)
We can represent these steps as a DAG:
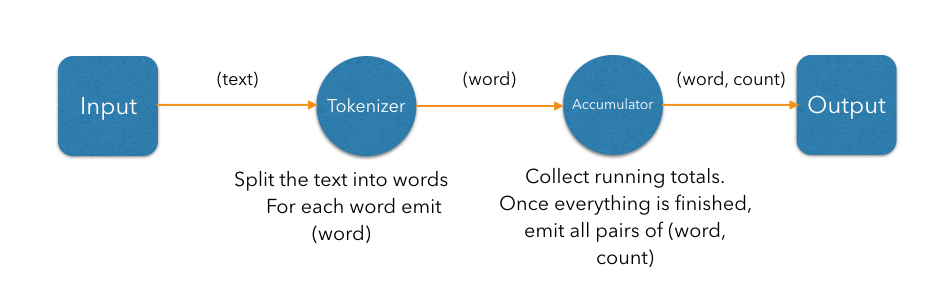
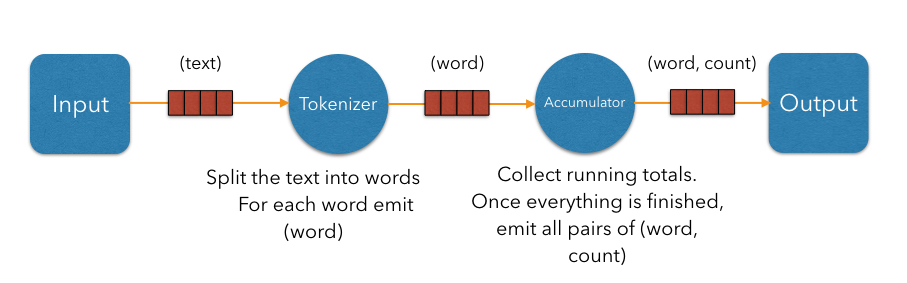
In the simplest case, the computation inside each vertex might be executed in turn in a single-threaded environment. To execute these steps in parallel, a producer vertex must publish its output items to a consumer vertex running on another thread. For this to work efficiently without interference between threads, we need to introduce concurrent queues between the vertices so each thread can do its processing at its own pace.
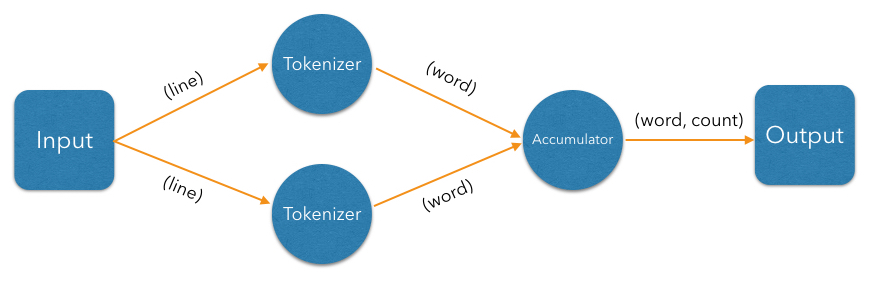
Now let us exploit the parallelizability of line parsing. We can have multiple tokenizer instances, each parsing its subset of lines:
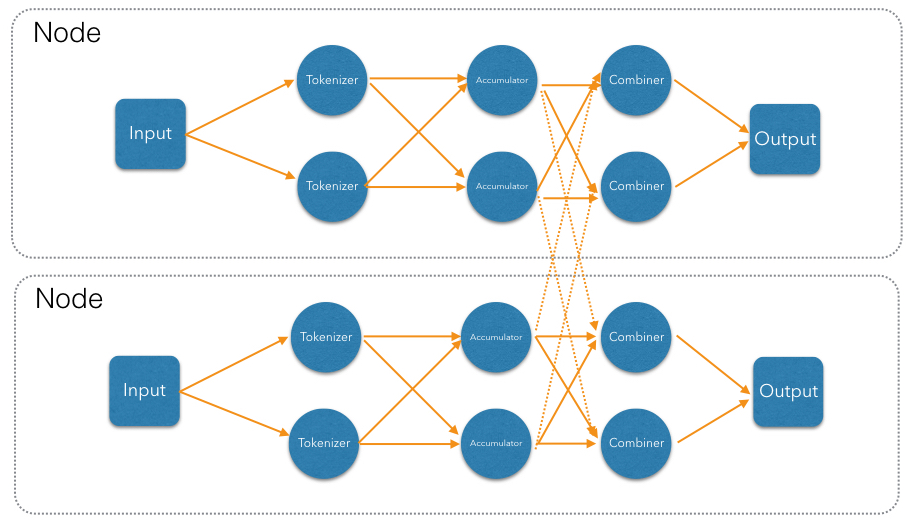
The accumulation step counts occurrences of individual words. Counting one word is independent of counting any other, but we must ensure that for each given word there is a unique instance of accumulator in charge of it, and will receive all entries with that word. This is called partitioning in Jet, and is achieved by creating a partitioned edge in the DAG, which ensures the words with same partitioning key are transmitted to the same instance of the vertex's processor.
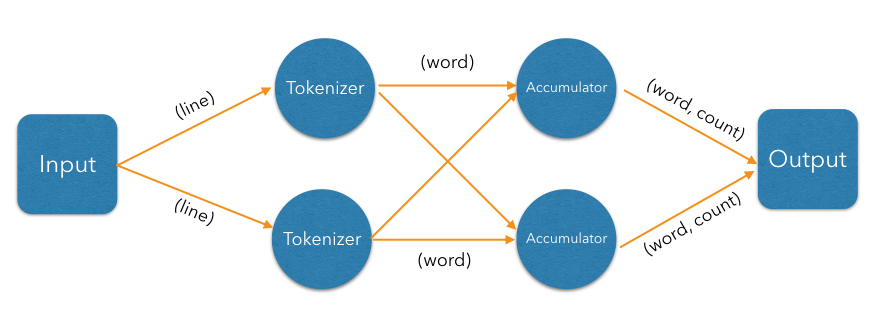
So far our DAG will produce correct results only when executed on a single Jet instance (cluster of size 1). With more members, each will compute just its local counts and then each member will race to push its result to the output map. Fixing this requires the addition of another vertex in the DAG, which will combine results from each local accumulator into a global result: