For this example we'll build a simple Jet job that monitors trading events on a stock market, categorizes the events by stock ticker, and reports the number of trades per time unit (the time window). In terms of DAG design, not much changes going from batch to streaming. This is how it looks:
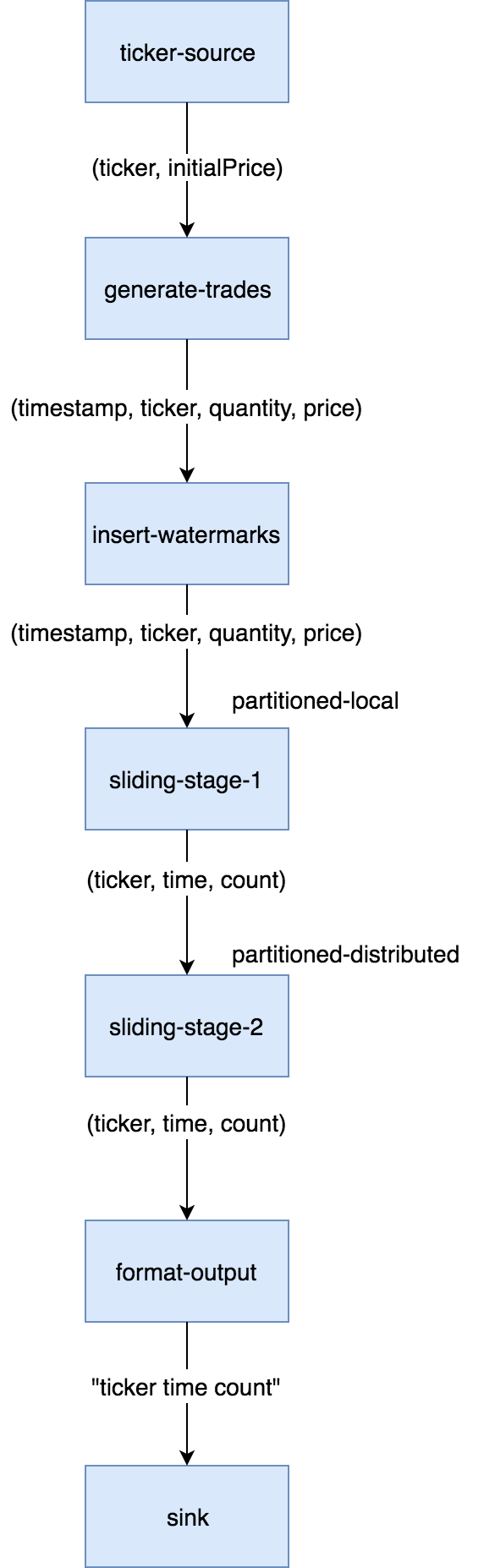
We have the same cascade of source, two-stage aggregation, and sink. The
source part consists of ticker-source that loads stock names
(tickers) from a Hazelcast IMap and generate-trades that retains this
list and randomly generates an infinite stream of trade events. A
separate vertex is inserting watermark items needed by the aggregation
stage and on the sink side there's another mapping vertex,
format-output, that transforms the window result items into lines of
text. The sink vertex writes these lines to a file.
Before we go on, let us point out that in the 0.5 release of Hazelcast Jet, the Pipeline API is still in infancy and doesn't support all the features needed for stream processing. Therefore the following example is given only in the Core API; with the next release we'll be able to present the much simpler code to do it in the Pipelines API.
If you studied the DAG-building code for the Word Count job, this code should look generally familiar:
WindowDefinition windowDef = WindowDefinition.slidingWindowDef(
SLIDING_WINDOW_LENGTH_MILLIS, SLIDE_STEP_MILLIS);
Vertex tickerSource = dag.newVertex("ticker-source",
SourceProcessors.readMapP(GenerateTradesP.TICKER_MAP_NAME));
Vertex generateTrades = dag.newVertex("generate-trades",
GenerateTradesP.generateTradesP(TRADES_PER_SEC_PER_MEMBER));
Vertex insertWatermarks = dag.newVertex("insert-watermarks",
Processors.insertWatermarksP(
Trade::getTime,
withFixedLag(GenerateTradesP.MAX_LAG),
emitByFrame(windowDef)));
Vertex slidingStage1 = dag.newVertex("sliding-stage-1",
Processors.accumulateByFrameP(
Trade::getTicker,
Trade::getTime, TimestampKind.EVENT,
windowDef,
counting()));
Vertex slidingStage2 = dag.newVertex("sliding-stage-2",
Processors.combineToSlidingWindowP(windowDef, counting()));
Vertex formatOutput = dag.newVertex("format-output",
formatOutput());
Vertex sink = dag.newVertex("sink",
SinkProcessors.writeFileP(OUTPUT_DIR_NAME));
tickerSource.localParallelism(1);
generateTrades.localParallelism(1);
return dag
.edge(between(tickerSource, generateTrades)
.distributed().broadcast())
.edge(between(generateTrades, insertWatermarks)
.isolated())
.edge(between(insertWatermarks, slidingStage1)
.partitioned(Trade::getTicker, HASH_CODE))
.edge(between(slidingStage1, slidingStage2)
.partitioned(Entry<String, Long>::getKey, HASH_CODE)
.distributed())
.edge(between(slidingStage2, formatOutput)
.isolated())
.edge(between(formatOutput, sink)
.isolated());
The source vertex reads a Hazelcast IMap, just like it did in the word
counting example. Trade generating vertex uses a custom processor that
generates mock trades. It can be reviewed
here.
The implementation of complete() is non-trivial, but most of the
complexity just deals with precision timing of events. For simplicity's
sake the processor must be configured with a local parallelism of 1;
generating a precise amount of mock traffic from parallel processors
would take more code and coordination.
The major novelty is the watermark-inserting vertex. It must be added
in front of the windowing vertex and will insert watermark items
according to the configured policy.
In this case we use the simplest one, withFixedLag, which will make
the watermark lag behind the top observed event timestamp by a fixed
amount. Emission of watermarks is additionally throttled, so that only
one watermark item per frame is emitted. The windowing processors emit
data only when the watermark reaches the next frame, so inserting it
more often than that would be just overhead.
The edge from insertWatermarks to slidingStage1 is partitioned; you
may wonder how that works with watermark items, since
- their type is different from the "main" stream item type and they don't have a partitioning key
- each of them must reach all downstream processors.
It turns out that Jet must treat them as a special case: regardless of the configured edge type, watermarks are routed using the broadcast policy.
The stage-1 processor will just forward the watermark it receives, along with any aggregation results whose emission it triggers, to stage 2.
The full code of this sample is in StockExchange.java and running it you'll get an endless stream of data accumulating on the disk. To spare your filesystem we've limited the execution time to 10 seconds.