Data Partitioning
As you read in the Sharding in Hazelcast section, Hazelcast shards are called Partitions. Partitions are memory segments, where each of those segments can contain hundreds or thousands of data entries, depending on the memory capacity of your system.
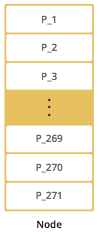
By default, Hazelcast offers 271 partitions. When you start a cluster member, it starts with these 271 partitions. The following illustration shows the partitions in a Hazelcast cluster with single member.
When you start a second node on that cluster (creating a Hazelcast cluster with 2 members), the partitions are distributed as shown in the following illustration.
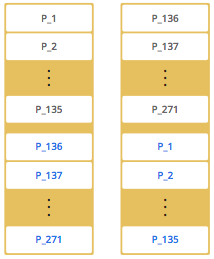
In the illustration, the partitions with black text are primary partitions, and the partitions with blue text are replica partitions (backups). The first member has 135 primary partitions (black), and each of these partitions are backed up in the second member (blue). At the same time, the first member also has the replica partitions of the second member's primary partitions.
As you add more members, Hazelcast one-by-one moves some of the primary and replica partitions to the new members, making all members equal and redundant. Only the minimum amount of partitions will be moved to scale out Hazelcast. The following is an illustration of the partition distributions in a Hazelcast cluster with 4 members.
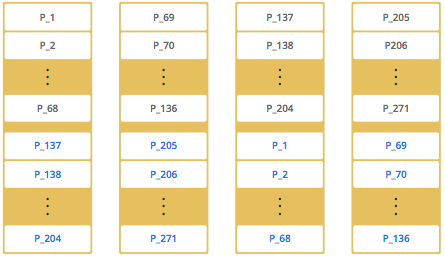
Hazelcast distributes the partitions equally among the members of the cluster. Hazelcast creates the backups of partitions and distributes them among the members for redundancy.
With Hazelcast 3.6, lite members are introduced. Lite members are a new type of members that do not own any partition. Lite members are intended for use in computationally-heavy task executions and listener registrations. Although they do not own any partitions, they can access partitions that are owned by other members in the cluster.
RELATED INFORMATION
Please refer to the Enabling Lite Members section.
 NOTE: Partition distributions in the above illustrations are for your convenience and for a more clearer description. Normally, the partitions are not distributed in an order (as they are shown in these illustrations), they are distributed randomly. The important point here is that Hazelcast equally distributes the partitions and their backups among the members.
NOTE: Partition distributions in the above illustrations are for your convenience and for a more clearer description. Normally, the partitions are not distributed in an order (as they are shown in these illustrations), they are distributed randomly. The important point here is that Hazelcast equally distributes the partitions and their backups among the members.
How the Data is Partitioned
Hazelcast distributes data entries into the partitions using a hashing algorithm. Given an object key (for example, for a map) or an object name (for example, for a topic or list):
- the key or name is serialized (converted into a byte array),
- this byte array is hashed, and
- the result of the hash is mod by the number of partitions.
The result of this modulo - MOD(hash result, partition count) - gives the partition in which the data will be stored, i.e. the partition ID. For ALL the members you have in your cluster, the partition ID for a given key will always be the same.
Partition Table
When you start a member, a partition table is created within it. This table stores the partition IDs and the cluster members they belong. The purpose of this table is to make all members (including lite members) in the cluster aware of this information, making sure that each member knows where the data is.
The oldest member in the cluster (the one that started first) periodically sends the partition table to all members. In this way, each member in the cluster is informed about any changes to the partition ownership. The ownerships may be changed when, for example, a new member joins the cluster, or when a member leaves the cluster.
NOTE: If the oldest member goes down, the next oldest member sends the partition table information to the other ones.
You can configure the frequency (how often) that the member sends the partition table the information by using the hazelcast.partition.table.send.interval system property. The property is set to every 15 seconds by default.
Repartitioning
Repartitioning is the process of redistribution of partition ownerships. Hazelcast performs the repartitioning in the following cases:
- When a member joins to the cluster.
- When a member leaves the cluster.
In these cases, the partition table in the oldest member is updated with the new partition ownerships.
Note that if a lite member joins or leaves a cluster, repartitioning is not triggered since lite members do not own any partitions.