JCache Eviction
Growing to an infinite size is in general not the expected behavior of caches. Implementing an expiry policy is one way to prevent the infinite growth but sometimes it is hard to define a meaningful expiration timeout. Therefore, Hazelcast JCache provides the eviction feature. Eviction offers the possibility to remove entries based on the cache size or amount of used memory (Hazelcast Enterprise Only) and not based on timeouts.
General information
Since a cache is designed for high throughput and fast reads, a lot of effort went into designing the eviction system as predictable as possible. All built-in implementations provide an amortized O(1) runtime. The default operation runtime is rendered as O(1) but can be faster than the normal runtime cost if the algorithm finds an expired entry while sampling.
Most importantly, in typical production system two common types of caches are found:
- Reference Caches: Caches for reference data are normally small and are used to speed up the de-referencing as a lookup table. Those caches are commonly tend to be small and contain a previously known, fixed number of elements (e.g. states of the USA or abbreviations of elements).
- Active DataSet Caches: The other type of caches normally caches an active data set. These caches run to their maximum size and evict the oldest or not frequently used entries to keep in memory bounds. They sit in front of a database or HTML generators to cache the latest requested data.
Hazelcast JCache eviction supports both types of caches using a slightly different approach based on the configured maximum size of the cache. For detailed information, please see the Eviction Algorithm section.
Eviction Policies
Hazelcast JCache provides two commonly known eviction policies, LRU and LFU, but loosens the rules for predictable runtime
behavior. LRU, normally recognized as Least Recently Used, is implemented as Less Recently Used, and LFU known as Least Frequently Used is implemented as
Less Frequently Used. The details about this difference is explained in the
Eviction Algorithm section.
Eviction Policies are configured by providing the corresponding abbreviation to the configuration as shown in the ICache Configuration section. As already mentioned, two built-in policies are available:
To configure the use of the LRU (Less Recently Used) policy:
<eviction size="10000" max-size-policy="ENTRY-COUNT" eviction-policy="LRU" />
And to configure the use of the LFU (Less Frequently Used) policy:
<eviction size="10000" max-size-policy="ENTRY-COUNT" eviction-policy="LFU" />
The default eviction policy is LRU. Therefore, Hazelcast JCache does not offer the possibility to perform no eviction.
Eviction Strategy
Eviction strategies implement the logic of selecting one or more eviction candidates from the underlying storage implementation and passing them to the eviction policies. Hazelcast JCache provides an amortized O(1) cost implementation for this strategy to select a fixed number of samples from the current partition that it is executed against.
The default implementation is com.hazelcast.cache.impl.eviction.impl.strategy.sampling.SamplingBasedEvictionStrategy which, as
mentioned, samples random 15 elements. A detailed description of the algorithm will be explained in the next section.
Eviction Algorithm
The Hazelcast JCache eviction algorithm is specially designed for the use case of high performance caches and with predictability in mind. The built-in implementations provide an amortized O(1) runtime and therefore provide a highly predictable runtime behavior which does not rely on any kind of background threads to handle the eviction. Therefore, the algorithm takes some assumptions into account to prevent network operations and concurrent accesses.
As an explanation of how the algorithm works, let's examine the following flowchart step by step.
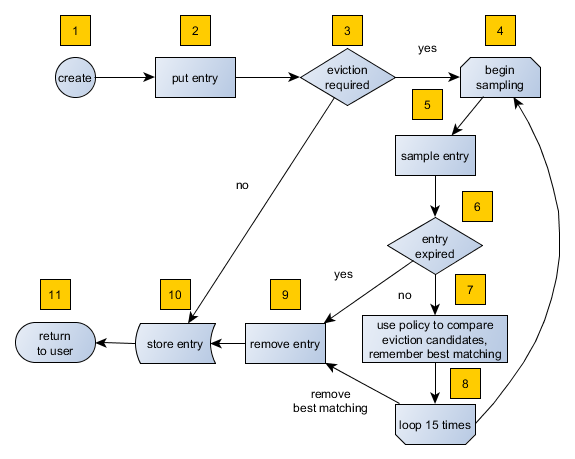
- A new cache is created. Without any special settings, the eviction is configured to kick in when the cache exceeds 10.000 elements and an LRU (Less Recently Used) policy is set up.
- The user puts in a new entry (e.g. a key-value pair).
- For every put, the eviction strategy evaluates the current cache size and decides if an eviction is necessary or not. If not the entry is stored in step 10.
- If eviction is required, a new sampling is started. The built-in sampler is implemented as an lazy iterator.
- The sampling algorithm selects a random sample from the underlying data storage.
- The eviction strategy tests the sampled entry to already be expired (lazy expiration). If expired, the sampling stops and the entry is removed in step 9.
- If not yet expired, the entry (eviction candidate) is compared to the last best matching candidate (based on the eviction policy) and the new best matching candidate is remembered.
- The sampling is repeated for 15 times and then the best matching eviction candidate is returned to the eviction strategy.
- The expired or best matching eviction candidate is removed from the underlying data storage.
- The new put entry is stored.
- The put operation returns to the user.
As seen by the flowchart, the general eviction operation is easy. As long as the cache does not reach its maximum capacity or you execute updates (put/replace), no eviction is executed.
To prevent network operations and concurrent access, as mentioned earlier, the cache size is estimated based on the size of the currently handled partition. Due to the imbalanced partitions, the single partitions might start to evict earlier than the other partitions.
As mentioned in the General Information section, typically two types of caches are found in the production systems. For small caches, referred to as Reference Caches, the eviction algorithm has a special set of rules depending on the maximum configured cache size. Please see the Reference Caches section for details. The other type of cache is referred to as Active DataSet Cache, which in most cases makes heavy use of the eviction to keep the most active data set in the memory. Those kinds of caches using a very simple but efficient way to estimate the cluster-wide cache size.
All of the following calculations have a well known set of fixed variables:
GlobalCapacity: The user defined maximum cache size (cluster-wide).PartitionCount: The number of partitions in the cluster (defaults to 271).BalancedPartitionSize: The number of elements in a balanced partition state,BalancedPartitionSize := GlobalCapacity / PartitionCount.Deviation: An approximated standard deviation (tests proofed it to be pretty near),Deviation := sqrt(BalancedPartitionSize).
Reference Caches
A Reference Cache is typically small and the number of elements to store in the reference caches is normally known prior to creating the cache. Typical examples of reference caches are lookup tables for abbreviations or the states of a country. They tend to have a fixed but small element number and the eviction is an unlikely event and rather undesirable behavior.
Since an imbalanced partition is the worst problem in the small and mid-sized caches than for the caches with millions of entries, the normal estimation rule (as discussed in a bit) is not applied to these kinds of caches. To prevent unwanted eviction on the small and mid-sized caches, Hazelcast implements a special set of rules to estimate the cluster size.
To adjust the imbalance of partitions as found in the typical runtime, the actual calculated maximum cache size (as known as the eviction threshold) is slightly higher than the user defined size. That means more elements can be stored into the cache than expected by the user. This needs to be taken into account especially for large objects, since those can easily exceed the expected memory consumption!
Small caches:
If a cache is configured with no more than 4.000 element, this cache is considered to be a small cache. The actual partition
size is derived from the number of elements (GlobalCapacity) and the deviation using the following formula:
MaxPartitionSize := Deviation * 5 + BalancedPartitionSize
This formula ends up with big partition sizes which summed up exceed the expected maximum cache size (set by the user), but since the small caches typically have a well known maximum number of elements, this is not a big issue. Only if the small caches are used for a use case other than using it as a reference cache, this needs to be taken into account.
Mid-sized caches
A mid-sized cache is defined as a cache with a maximum number of elements that is bigger than 4.000 but not bigger than
1.000.000 elements. The calculation of mid-sized caches is similar to that of the small caches but with a different
multiplier. To calculate the maximum number of elements per partition, the following formula is used:
MaxPartitionSize := Deviation * 3 + BalancedPartitionSize
Active DataSet Caches
For large caches, where the maximum cache size is bigger than 1.000.000 elements, there is no additional calculation needed. The maximum
partition size is considered to be equal to BalancedPartitionSize since statistically big partitions are expected to almost
balance themselves. Therefore, the formula is as easy as the following:
MaxPartitionSize := BalancedPartitionSize
Cache size estimation
As mentioned earlier, Hazelcast JCache provides an estimation algorithm to prevent cluster-wide network operations, concurrent access to other partitions and background tasks. It also offers a highly predictable operation runtime when the eviction is necessary.
The estimation algorithm is based on the previously calculated maximum partition size (please see the Reference Caches section and Active DataSet Caches section) and is calculated against the current partition only.
The algorithm to reckon the number of stored entries in the cache (cluster-wide) and if the eviction is necessary is shown in the following pseudo-code example:
RequiresEviction[Boolean] := CurrentPartitionSize >= MaxPartitionSize