Map
Map Overview
Hazelcast Map (IMap) extends the interface java.util.concurrent.ConcurrentMap and hence java.util.Map. It is the distributed implementation of Java map. You can perfrom operations like reading and writing from/to a Hazelcast map with the well known get and put methods.
How Distributed Map Works
Hazelcast will partition your map entries and almost evenly distribute onto all Hazelcast members. Each member carries approximately "(1/n * total-data) + backups", n being the number of nodes in the cluster. For example, if you have a node with 1000 objects to be stored in the cluster, and then you start a second node, each node will both store 500 objects and back up the 500 objects in the other node.
Let's create a Hazelcast instance (node) and fill a map named Capitals with key-value pairs using the following code.
public class FillMapMember {
public static void main( String[] args ) {
HazelcastInstance hzInstance = Hazelcast.newHazelcastInstance();
Map<String, String> capitalcities = hzInstance.getMap( "capitals" );
capitalcities.put( "1", "Tokyo" );
capitalcities.put( "2", "Paris” );
capitalcities.put( "3", "Washington" );
capitalcities.put( "4", "Ankara" );
capitalcities.put( "5", "Brussels" );
capitalcities.put( "6", "Amsterdam" );
capitalcities.put( "7", "New Delhi" );
capitalcities.put( "8", "London" );
capitalcities.put( "9", "Berlin" );
capitalcities.put( "10", "Oslo" );
capitalcities.put( "11", "Moscow" );
...
...
capitalcities.put( "120", "Stockholm" )
}
}
When you run this code, a node is created with a map whose entries are distributed across the node's partitions. See the below illustration. For now, this is a single node cluster.
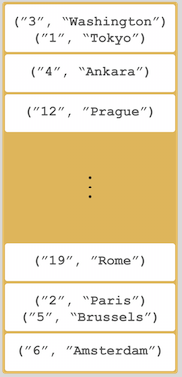
 NOTE: Please note that some of the partitions will not contain any data entries since we only have 120 objects and the partition count is 271 by default. This count is configurable and can be changed using the system property
NOTE: Please note that some of the partitions will not contain any data entries since we only have 120 objects and the partition count is 271 by default. This count is configurable and can be changed using the system property hazelcast.partition.count. Please see the System Properties section.
Now, let's create a second node by running the above code again. This will create a cluster with 2 nodes. This is also where backups of entries are created; remember the backup partitions mentioned in the Hazelcast Overview section. The following illustration shows two nodes and how the data and its backup is distributed.

As you see, when a new member joins the cluster, it takes ownership and loads some of the data in the cluster. Eventually, it will carry almost "(1/n * total-data) + backups" of the data, reducing the load on other nodes.
HazelcastInstance::getMap returns an instance of com.hazelcast.core.IMap which extends
the java.util.concurrent.ConcurrentMap interface. Methods like
ConcurrentMap.putIfAbsent(key,value) and ConcurrentMap.replace(key,value) can be used
on the distributed map, as shown in the example below.
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import java.util.concurrent.ConcurrentMap;
HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance();
Customer getCustomer( String id ) {
ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap( "customers" );
Customer customer = customers.get( id );
if (customer == null) {
customer = new Customer( id );
customer = customers.putIfAbsent( id, customer );
}
return customer;
}
public boolean updateCustomer( Customer customer ) {
ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap( "customers" );
return ( customers.replace( customer.getId(), customer ) != null );
}
public boolean removeCustomer( Customer customer ) {
ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap( "customers" );
return customers.remove( customer.getId(), customer );
}
All ConcurrentMap operations such as put and remove might wait if the key is locked by another thread in the local or remote JVM. But, they will eventually return with success. ConcurrentMap operations never throw a java.util.ConcurrentModificationException.
Also see:
- Data Affinity section.
- Map Configuration with wildcards.
- Map Configuration section for a full description of Hazelcast Distributed Map configuration.